
自分のYouTube動画を海外にも届けたい――そう考えたとき、字幕だけでなく 吹き替え音声 があると視聴体験は大きく変わります。以前はプロのナレーターに依頼するか、自分で外国語を話す必要がありましたが、ElevenLabsのTTS APIの登場で状況が変わりました。
この記事では、私が実際に運用している YouTube動画の多言語吹き替え音声を自動生成するワークフロー を、再現可能な形で紹介します。使うのはClaude、Python、ffmpeg、ElevenLabs API。テキスト処理の中核をClaudeが担い、音声生成と加工をPython + ffmpegが自動化します。特別な機材は不要で、個人クリエイターでも始められます。
ワークフロー全体像
このワークフローは7つのステップで構成されています。
動画ファイル
↓ Step 1: 文字起こし + Python前処理 + Claude整形
日本語テキスト
↓ Step 2: Claudeで翻訳 + TTS最適化
吹き替え用字幕 (_en_dub.srt)
↓ Step 3: ElevenLabs TTS API
cue単位の音声ファイル (.mp3)
↓ Step 4: ffmpegタイムライン構築(★単純連結ではなく絶対時刻配置)
タイムライン音声 (.wav)
↓ Step 5: マスタリング
吹き替え音声 (.mp3)
↓ Step 6: Premiere Proで主音声ミュート + BGM・SE合成
完成版吹き替え音声 (.mp3)
↓ Step 7: アップロード
YouTube Studio(吹き替え音声トラック)
各ステップで使用するツールは以下の通りです。
| ステップ | 使用ツール | 役割 |
|---|---|---|
| Step 1 | Premiere Pro / Whisper + Python + Claude | 文字起こし・前処理・テキスト整形 |
| Step 2 | Claude | 翻訳・吹き替え用字幕作成・TTS最適化 |
| Step 3 | Python + ElevenLabs API | TTS音声生成 |
| Step 4 | ffmpeg | 速度調整・タイムライン配置 |
| Step 5 | ffmpeg | ゲイン調整・リミッタ・MP3出力 |
| Step 6 | Premiere Pro | 主音声ミュート・BGM/SE合成 |
| Step 7 | YouTube Studio | 吹き替え音声の登録 |
Step 1〜2の テキスト処�理フェーズ がこのワークフローで最も知的労力がかかる部分で、ここにClaude(LLM)の力が不可欠です。Step 3〜5はスクリプトとffmpegによる自動処理です。
前提環境と事前準備
必要なツール・アカウント
以下のツールとアカウントを事前に用意します。
- Claude(Anthropic)— 翻訳・テキスト最適化の中核ツール
- Python 3.10以上
- ffmpeg / ffprobe(パスが通った状態)
- ElevenLabsアカウント(Starter Plan以上)
- Premiere Pro(文字起こし用、Whisperでも代替可)
- Pythonライブラリ:
requests,python-dotenv、(Whisper使用時はfaster-whisperも)
pip install requests python-dotenv faster-whisper
ElevenLabs APIキーの取得
- ElevenLabsでアカウントを作成
- ダッシュボードの Profile + API Key セクションからAPIキーをコピー
- サイドバーの「ボイス」→「探索」から、言語やカテゴリ(ナレーション、会話的など)でフィルタリングして気に入った音声を見つける
- 音声の詳細画面からVoice IDをコピー
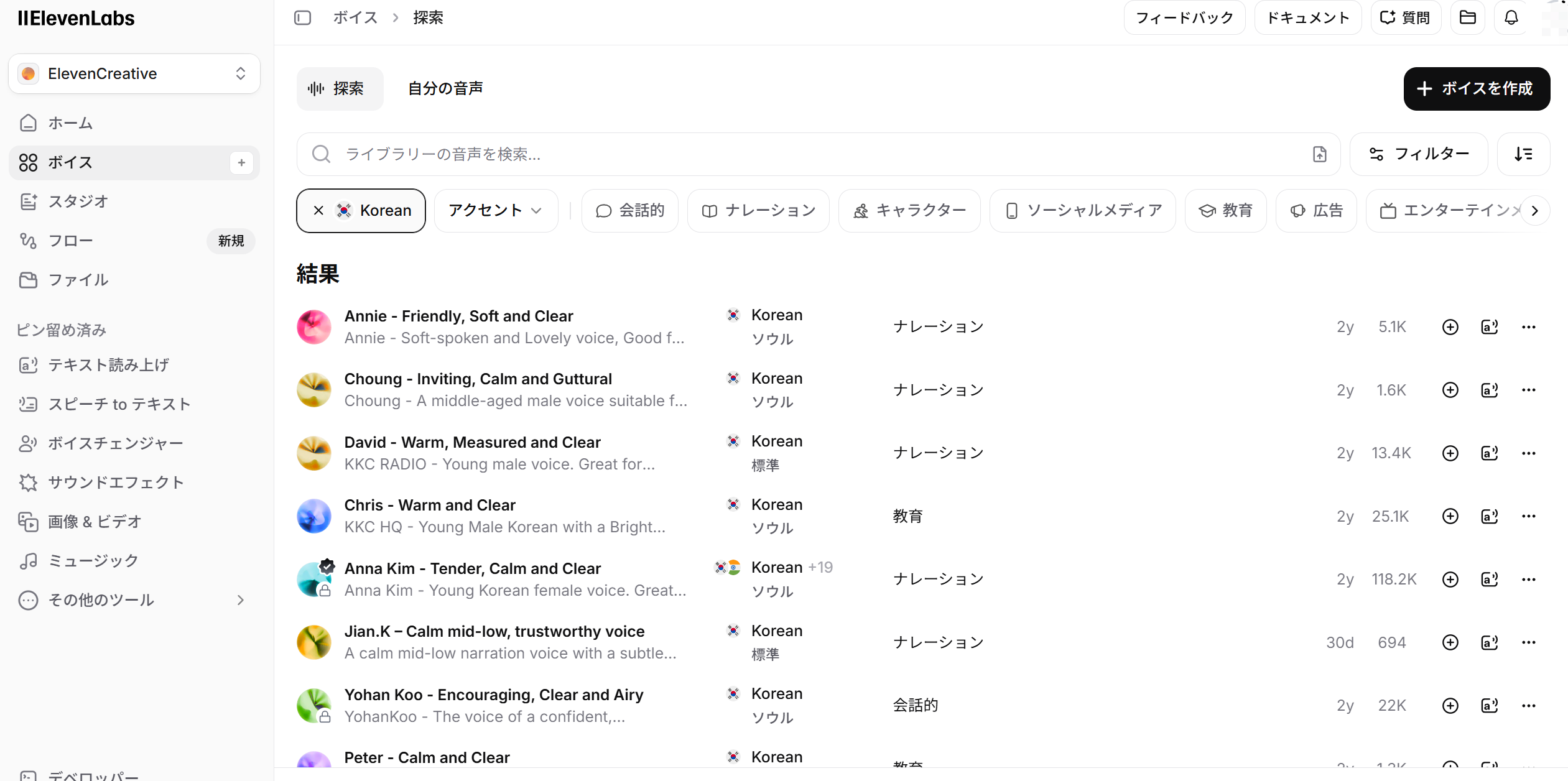
プロジェクトのルートに.envファイルを作成し、APIキーとVoice IDを設定します。
ELEVENLABS_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx
ELEVENLABS_VOICE_ID_EN=UgBBYS2sOqTuMpoF3BR0
ELEVENLABS_VOICE_ID_KR=PDoCXqBQFGsvfO0hNkEs
上記のVoice IDは、私が実際に使用している音声です。ElevenLabsのボイスライブラリから試聴して気に入ったものを選びました。

Voice IDは秘密情報ではなく、ElevenLabsの公開ライブラリにある音声のIDなので、そのまま使っていただいても構いません。もちろん、ご自身のチャンネルに合う音声を探して差し替えるのがおすすめです。
使用可能な音声の一覧は、ElevenLabs APIの/voicesエンドポイントで確認できます。
import requests, os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("ELEVENLABS_API_KEY")
resp = requests.get(
"https://api.elevenlabs.io/v1/voices",
headers={"xi-api-key": api_key},
)
for v in resp.json()["voices"]:
print(f"{v['voice_id']} {v['name']} ({v['category']})")
Claudeの活用:なぜLLMが不可欠なのか
このワークフローでは、Python + ffmpegによる自動処理だけでなく、 Claude(LLM)が中核的な役割 を担います。
Pythonだけでは限界がある理由
文字起こしの前処理や翻訳字幕の作成には、 文脈を理解した判断 が必要です。Pythonスクリプトで機械的にできるのはフィラー除去や文字列置換などの定型処理まで。以下のような作業はPythonでは対応できません。
- 文脈に基づくテキスト整形: 話者の意図を汲んで口語を読みやすい文章に再構成する
- 翻訳: ニュアンスを維持した自然な多言語翻訳
- TTS最適化: 指定された秒数枠に収まるよう、意味を保ったままテキストを圧縮する
- 固有名詞の文脈判断: 同じ音でも文脈によって正しい表記が異なるケース
つまり、このワークフローは 「Pythonで機械的に処理できる部分」と「LLMに意味理解を任せる部分」の二段構え で成り立っています。
Claudeを推奨する理由
翻訳や吹き替え用字幕の作成にはChatGPT(GPT-5.4)でも同等のことは可能です。ただし、 吹き替え用字幕の作成(TTS最適化)においてはClaudeが明確に優れている と感じています。
吹き替え用字幕の作成では「この文を3.5秒枠に収まるよう、15語以内で意味を保って圧縮してください」といった制約付きの指示が大量に発生します。Claudeはこうした 指定された時間枠に良い具合にテキストを圧縮する器用さ に長けています。単に文を短くするだけでなく、TTSが読み上げたときの自然さ(息継ぎの位置、contractionの使い方、列挙の圧縮)まで考慮した出力が安定して得られます。
このフロー構築時に実際にClaudeで吹き替え用字幕を作成したところ、181cueの字幕が146cueに最適化され(19.3%削減)ました。1cueずつの速度比(テキスト長 / 表示時間)がすべて1.3倍以内��に収まるよう調整するという繊細な作業を、Claudeは高い精度でこなしてくれます。
Step 1:字幕(テキスト)を作成する
文字起こしの方法
吹き替えの起点となる日本語テキストを用意します。方法は大きく2つあります。
方法1: Premiere Proの文字起こし機能(おすすめ)
私が実際に使っているのはこちらです。Premiere Proには 音声のテキスト変換 機能が組み込まれており、映像のコンテキストも考慮した高精度な文字起こしが得られます。手順は簡単で、Premiere Proのキャプションパネルから「文字起こし」を実行し、結果を テキスト(.txt)形式でエクスポート するだけです。
Premiere Proの文字起こしは動画の映像情報も解析に使うため、Whisper単体と比べて固有名詞や専門用語の認識精度が高く感じます。すでにPremiere Proで編集している場合は、追加のセットアップなしですぐに使えるのも大きなメリットです。
なお、Premiere Proにもフィラーワード(「えー」「あのー」等)を自動除去する機能がありますが、 これを適用せずにそのままエクスポートする ことを推奨します。フィラー除去を適用するとタイムコードが細分化されすぎてしまい、このあとClaude に渡して意味理解ベースの整形を行う際に、文脈の把握精度が落ちる可能性があります。フィラーの除去はClaude側で文脈を見ながら行うほうが、結果的に品質の高いテキストが得られます。
方法2: Whisper(faster-whisper)を使う方法
Premiere Proがない環境では、faster-whisperが強力な代替手段です。GPUがあればlarge-v3-turboモデルで高速かつ高精度な文字起こしが可能です。
python transcribe.py "input_video.mp4" "output_dir/" \
--model large-v3-turbo \
--language ja \
--beam-size 5
from faster_whisper import WhisperModel
model = WhisperModel("large-v3-turbo", device="cuda", compute_type="float16")
segments, info = model.transcribe(
"input_video.mp4",
language="ja",
beam_size=5,
vad_filter=True,
vad_parameters={"min_silence_duration_ms": 500},
word_timestamps=True,
temperature=0.0,
)
vad_filter=Trueで無音区間を自動検出し、セグメント分割が改善されます。出力はSRT形式で保存します。
どちらの方法でも、このあとの前処理と翻訳のステップは同じです。
前処理:Python+Claudeの二段構え
文字起こしの生出力はそのままでは翻訳に使えません。前処理は Pythonで機械的に処理する段階 と Claudeで意味理解して整形する段階 の二段構えです。
第1段階:Pythonによる機械的な前処理
以下の3つはPythonスクリプトで自動化できます。
フィラー除去: 「えー」「あのー」「うーん」など、テキスト全体がフィラーだけで構成されるセグメントを丸ごと除去します。
FILLER_ONLY = {
"はい", "はい。", "えー", "えーと", "えっと",
"うーん", "うん", "あの", "あー", "おー",
"そう", "そうです", "そうですね", "ね", "で",
}
if segment["text"].strip() in FILLER_ONLY:
continue # このセグメントを丸ごとスキップ
また、文頭のフィラー(「えーと、では次に...」の「えーと、」部分)も正規表現で除去します。
固有名詞の機械的な置換: Whisperは専門用語や固有名詞を高い確率で誤認識します。あらかじめ「誤認識パターン→正しい表記」の置換リストを用意しておきます。
# チャンネル固有の置換リストの例
REPLACEMENTS = [
("新学校", "進学校"), # 同音異字
("元受け", "元請け"), # 漢字誤り
("下受け", "下請け"), # 漢字誤り
("チャンネル誤認識A", "正しいチャンネル名"), # 固有名詞
]
for old, new in REPLACEMENTS:
text = text.replace(old, new)
この置換リストは最初から完璧に作る必要はありません。字幕作成を繰り返す中で新しい誤認識パターンを見つけたら、Claudeに「この誤認識を対応表に追加しておいて」と指示しておけば、動画を作れば作るほど置換リストが充実し、前処理の精度が上がっていきます。
セグメント結合: 短すぎるセグメントは隣接セグメントと結合します。
def should_merge(current, next_seg, max_gap=0.8, max_duration=16.0, max_chars=160):
gap = next_seg["start"] - current["end"]
if gap > max_gap: # 間が0.8秒以上空いていたら別セグメント
return False
if next_seg["end"] - current["start"] > max_duration: # 結合後16秒超
return False
if len(current["text"] + next_seg["text"]) > max_chars: # 結合後160字超
return False
return True
第2段階:Claudeによる意味理解ベースの整形
Pythonの機械処理を通しても、文字起こしの生テキストはまだ「話し言葉の書き起こし」のままです。実際の例を見てみましょう。
Whisper生出力(Python前処理後):
えーとですね今日はまあ設定周りの話をちょっとしたいなと思ってまして
まあ結構つまずくポイントっていうかですねそのへんをまとめていきます
Claudeで整形した結果:
今回は設定周りでつまずきやすいポイントをまとめて解説します。
ここで起きていることは単なる「誤字修正」ではありません。
- 「えーとですね」「まあ」「ちょっと」「っていうかですね」→ 口語のフィラー的な表現を除去
- 2文にまたがっていた内容を1文に凝縮
- 話者の意図を汲み取り、翻訳しやすい明確な文に再構成
もう1つ、配信動画の冒頭部分の例です。
Whisper生出力:
はいみなさんこんにちは
今日はちょっと天気が良くてですね散歩がてら来たんですけど
まあそれはさておきですね今日の本題なんですが
Claudeで整形した結果:
(冒頭の挨拶・雑談を削除し、テーマ部分から開始)
配信動画では冒頭に挨拶や雑談が数分入ることが多いですが、吹き替え音声ではテーマに直結した内容だけが必要です。「ここからがテーマの本題」という判断はPythonにはできず、 文脈を理解するClaudeだからこそ可能な処理 です。
このように、前処理の第1段階(Python)でノイズを機械的に除去し、第2段階(Claude)で話し言葉を自然な文章に再構成するという流れが、翻訳精度を大きく左右します。
Step 2:Claudeで翻訳字幕を作成しTTS最適化する
翻訳のポイント
前処理済みの日本語テキストを、Claudeに渡して対象言語に翻訳します。翻訳と同時に、TTS用の最適化も一括で指示するのが効率的です。
Claudeへの翻訳指示では、以下のポイントを明示します。
全言語共通:
- 話し言葉として自然な翻訳にすること。字幕翻訳とは異なり、TTSで読み上げるため書き言葉的な表現は避ける
- 各cueは表示時間の枠内でTTSが読み切れるテキスト量に収めること
英語の場合:
- contractions を積極使用("can not" → "can't"、"do not" → "don't")
- 冗長な表現をカット("Furthermore" → "Also"、"In order to" → "To")
韓国語の場合:
- 해요体(ヘヨチェ)に統一する。韓国語には丁寧さのレベルが異なる複数の文体があります。해요体は日本語の「〜です・〜ます」に相当するカジュアルな丁寧語で、YouTube動画の語りかけ口調に最も自然です。一方、합니다体(ハムニダチェ)はニュースや公式文書で使われるフォーマルな敬語で、TTSで読み上げると堅く不自然に聞こえます
- 漢語系の長い複合語はTTSが一息で読み上げてしまうため、分解して自然なリズムにする(例: 「충분조건」→「충분한 조건」)
実際の変換例を見てみましょう。
日本語(Claude整形済み):
興味があるとか好きだなと思うこと以外、人ってそもそも長い時間はできないじゃないですか。
英語の吹き替え用字幕(_en_dub.srt、Claude作成):
Other than things you're interested in or things you like,
you can't spend long hours on them, right?
韓国語の吹き替え用字幕(_kr_dub.srt、Claude作成):
흥미가 있거나, 좋아하지 않으면
오랜 시간을 들일 수 없잖아요
Claudeは日本語の口語ニュアンス(「〜じゃないですか」という同意を求める語尾)を、英語では"right?"、韓国語では"〜잖아요"(해요体の同意表現)に適切に変換しています。こうした ニュアンスレベルの翻訳精度 が、機械翻訳ではなくClaudeを使う理由です。
TTS向け最適化ルール
翻訳後の字幕をTTS用に最適化した「吹き替え用字幕」を作成します。ファイル名は動画名_en_dub.srtのように言語コード + _dubを付けて、表示用字幕と区別します。
核心ルール: 1cue = 1完結文
通常の字幕では1つの文が複数cueにまたがることがありますが、TTS用SRTでは 1つのcueに1つの完結した文 を入れます。TTSエンジンはcue単位で読み上げるため、文の途中で切れると不自然なイントネーションになります。
具体例で見てみましょう。元の日本語が「基礎練習を毎日続けることが上達の近道�ですが、ただ量をこなすだけでは効率が悪い」という文だった場合、以下のように変換します。
通常の表示用字幕(_en.srt) — 画面に表示するための短い区切り:
1
00:00:03,200 --> 00:00:05,800
Practicing the basics every day
2
00:00:05,800 --> 00:00:08,500
is the fastest way to improve,
3
00:00:08,500 --> 00:00:11,200
but just doing a lot of practice
isn't very efficient.
TTS用の吹き替え字幕(_en_dub.srt) — 1cueに1完結文:
1
00:00:03,200 --> 00:00:11,200
Practicing basics daily is the fastest way to improve, but just doing a lot isn't efficient.
表示用字幕では3cueに分かれていた文を、吹き替え用字幕では1cueにまとめています。TTSは00:00:03,200の地点でこの1文を一息で読み上げるため、自然なイントネーションになります。
もう1つ、テキスト短縮の例も見てみましょう。
| 変換前(翻訳そのまま) | 変換後(TTS最適化) | 短縮ポイント |
|---|---|---|
| It is important to understand that... | You need to understand that... | 冗長な書き出しをカット |
| In order to achieve this goal | To achieve this | 前置詞句を圧縮 |
| Furthermore, you should also consider | Also, consider | 接続詞と冗長語を削減 |
| ルール | 詳細 |
|---|---|
| 1cueの文字数 | 英語: 15-20語、韓国語: 25-35文字 |
| 超短cue | 1秒未満のcueは隣接に統合 |
| 息継ぎ | 20語以上の連続テキストにはカンマで区切りを入れる |
| 数字 | 韓国語ではハングルで綴る(TTSの数字読みが不安定) |
速度予測の目安(英語)
1語 ≈ 120-150ms
2秒枠 → 最大13-16語
3秒枠 → 最大20-25語
4秒枠 → 最大27-33語
cueの表示時間に対してテキストが長すぎると、速度調整の上限を超えて失敗します。上記の目安を参考にテキスト量を調整してください。
Step 3:ElevenLabs APIで音声を生成する
ここがこのワークフローの核心です。Dub SRTの各cueをElevenLabs APIに送り、音声ファイルを取得します。
APIの基本仕様
エンドポイント: POST https://api.elevenlabs.io/v1/text-to-speech/{voice_id}
認証ヘッダー: xi-api-key: <your-api-key>
レスポンス: audio/mpeg(MP3バイナリ)
リクエストボディ:
{
"text": "The text to synthesize.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
stabilityは声の一貫性(高いほど安定、低いほど表現力豊か)、similarity_boostは選択した音声への忠実度を制御します。吹き替え用途では上記のバランスがおすすめです。
Pythonスクリプトの実装
処理の全体フローは以下の通りです。
import requests, hashlib, json, re, subprocess
from pathlib import Path
from dotenv import load_dotenv
API_BASE = "https://api.elevenlabs.io/v1"
def tts_generate(api_key, voice_id, text, output_path,
model_id="eleven_flash_v2_5", max_retries=3):
"""1つのテキストからMP3音声を生成する"""
url = f"{API_BASE}/text-to-speech/{voice_id}"
headers = {
"xi-api-key": api_key,
"Content-Type": "application/json",
}
body = {
"text": text,
"model_id": model_id,
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
}
for attempt in range(max_retries):
resp = requests.post(url, headers=headers, json=body,
stream=True, timeout=60)
if resp.status_code == 200:
with open(output_path, "wb") as f:
for chunk in resp.iter_content(chunk_size=4096):
f.write(chunk)
return
if resp.status_code in (429, 500, 502, 503):
wait = 2 ** (attempt + 1)
time.sleep(wait)
continue
resp.raise_for_status()
raise RuntimeError(f"TTS failed after {max_retries} retries")
SRT解析も自前で実装します。正規表現でcue番号、タイムスタンプ、テキストを抽出します。
SRT_BLOCK_RE = re.compile(
r"(?ms)^\s*(\d+)\s*\n"
r"(\d{2}:\d{2}:\d{2},\d{3}) --> (\d{2}:\d{2}:\d{2},\d{3})\s*\n"
r"(.*?)(?=\n{2,}|\Z)"
)
def parse_ts(value):
"""SRTタイムスタンプをミリ秒に変換"""
hh, mm, rest = value.split(":")
ss, ms = rest.split(",")
return ((int(hh) * 60 + int(mm)) * 60 + int(ss)) * 1000 + int(ms)
def parse_srt(path):
text = Path(path).read_text(encoding="utf-8-sig")
cues = []
for m in SRT_BLOCK_RE.finditer(text):
cues.append({
"index": int(m.group(1)),
"start_ms": parse_ts(m.group(2)),
"end_ms": parse_ts(m.group(3)),
"text": m.group(4).strip(),
})
return cues
各cueに対してtts_generate()を呼び出し、個別のMP3ファイルを取得します。
キャッシュとリトライ戦略
APIコストを抑えるため、生成済み音声はキャッシュします。テキスト・Voice ID・モデルIDからSHA1ハッシュを生成し、キャッシュキーとして使います。
def build_cache_key(voice_id, model_id, text):
payload = f"{voice_id}\n{model_id}\n{text}".encode("utf-8")
return hashlib.sha1(payload).hexdigest()
cache_dir = Path("_tts_cache")
cache_dir.mkdir(exist_ok=True)
key = build_cache_key(voice_id, model_id, cue["text"])
cached = cache_dir / f"{key}.mp3"
if cached.exists():
# キャッシュヒット → API呼び出しをスキップ
shutil.copy(cached, output_path)
else:
tts_generate(api_key, voice_id, cue["text"], cached, model_id)
shutil.copy(cached, output_path)
テキストを修正するとハッシュが変わるため、旧キャッシュは自動的に無効化されます。テスト実行(最初の5cueだけ生成)で使ったキャッシュは本番実行でもそのまま再利用されるので、クレジットの無駄がありません。
Step 4:ffmpegでタイムライン構築
cue単位のMP3が揃ったら、ffmpegで1本のタイムライン音声にまとめます。
速度調整(atempo)
TTS音声の長さがcueの表示時間より長い場合、atempoフィルタで再生速度を調整します。
def adjust_speed(input_path, output_path, tempo):
"""WAV音声の再生速度をtempo倍に調整"""
subprocess.run([
"ffmpeg", "-y", "-hide_banner", "-loglevel", "error",
"-i", str(input_path),
"-filter:a", f"atempo={tempo:.4f}",
"-c:a", "pcm_s16le", "-ar", "48000", "-ac", "2",
str(output_path),
], check=True)
速度比(ratio)の判定基準は以下の通りです。
| ratio | 判定 |
|---|---|
| 1.0以下 | 調整不要(音声がcue枠より短い) |
| 1.0〜1.3 | atempoで加速して収める |
| 1.3超 | テキストが長すぎる→吹き替え用字幕側を修正 |
英語の場合は1.5倍まで許容できますが、1.3倍を超えると早口感が出始めます。
無音ベース+adelayで絶対時刻配置
ここが タイムライン構築の肝 です。YouTubeの吹き替え音声は元動画と長さが完全一致していなければ登録できません。TTS音声を単純に前詰めで連結すると、cue間の無音区間が消えるため大抵の場合は元動画より短くなってしまい、アップロードが弾かれます。
そこで、まず動画全尺の無音WAVをベースとして作り、各cueの音声を SRTの開始時刻に基づいて絶対位置に配置 する方式を取ります。
# 動画全尺の無音WAVを生成
subprocess.run([
"ffmpeg", "-y", "-hide_banner", "-loglevel", "error",
"-f", "lavfi", "-i", "anullsrc=r=48000:cl=stereo",
"-t", f"{total_duration_sec:.3f}",
"-c:a", "pcm_s16le", "silence.wav",
], check=True)
各cueの音声にadelayフィルタを適用して、SRTの開始時刻(ミリ秒)に配置します。
# ffmpegフィルタグラフの例
[1:a]adelay=3200|3200[d0] # cue1を3.2秒地点に配置
[2:a]adelay=8500|8500[d1] # cue2を8.5秒地点に配置
[3:a]adelay=15000|15000[d2] # cue3を15.0秒地点に配置
この方式により、途中のcueが失敗しても後続のタイミングがずれません。
amixによるミックスダウン
最後にamixフィルタで無音ベースと全cueを合成します。
[0:a][d0][d1][d2]amix=inputs=4:duration=first:dropout_transition=0:normalize=0[out]
重要: normalize=0を必ず指定してください。デフォルトのnormalize=1だと各入力の音量が1/Nに正規化され、cue数が多い(例: 150cue)とほぼ無音になります。
cue数が多い場合は30cueずつバッチ処理し、段階的にミックスします。フィルタグラフが長くなるため、-filter_complex_scriptでファイル経由で渡すのが安全です。
Step 5:マスタリングと品質検証
ゲイン調整とピークリミッタ
タイムライン音声にゲインとリミッタを適用し、最終MP3を出力します。
def apply_mastering(input_path, output_path, gain_db=7.0, limit_db=-1.0):
limit_linear = 10 ** (limit_db / 20) # dBFSを線形値に変換
subprocess.run([
"ffmpeg", "-y", "-hide_banner", "-loglevel", "warning",
"-i", str(input_path),
"-filter:a", f"volume={gain_db:.2f}dB,alimiter=limit={limit_linear:.4f}",
"-ar", "48000", "-ac", "2",
"-c:a", "libmp3lame", "-b:a", "192k",
str(output_path),
], check=True)
volume=7.0dB: TTS音声は元動画より控えめな音量になりがちなので増幅しますalimiter: ピークが-1.0dBFSを超えないようにクリッピングを防止します
レポートによる品質確認
生成結果をJSONレポートで確認します。
{
"input_cues": 171,
"ok_cues": 170,
"silenced_cues": 0,
"failed_cues": 0,
"skipped_empty_cues": 1,
"cache_hits": 5,
"duration_ok": true,
"max_ratio": 1.28
}
確認すべきポイントは以下の3つです。
- failed_cues = 0: すべてのcueが正常に生成されていること
- silenced_cues = 0: 無音で埋められたcueがないこと
- duration_ok = true: 出力MP3の長さが元動画と一致していること
最終検証として、ffmpegでデコードエラーがないことも確認します。
ffmpeg -v error -xerror -i output_dub.mp3 -f null NUL
# exit code 0 なら問題なし
Step 6:Premiere ProでBGM・SEと合成する
Step 5で出力したMP3はTTS音声のみで、BGM(背景音楽)やSE(効果音)が含まれていません。ここでPremiere Proの編集済みタイムラインを活用します。
元動画の編集プロジェクトに吹き替え音声トラックを追加するだけで、通常の動画書き出しと吹き替え音声の書き出しを同じタイムラインから行えます。
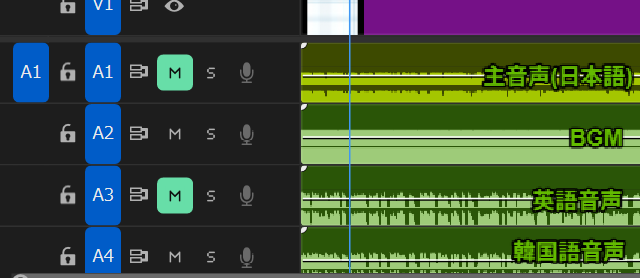
書き出しの手順は以下の通りです。
- 日本語動画の書き出し: 主音声(A1)+ BGM(A2)を有効にして通常通り動画(.mp4)をエクスポート
- 英語吹き替え音声の書き出し: 主音声(A1)をミュートし、英語音声(A3)+ BGM(A2)の状態でオーディオのみ(.mp3)をエクスポート
- 韓国語吹き替え音声の書き出し: 同様に韓国語音声(A4)+ BGM(A2)でエクスポート
最終的な出力は以下の3ファイルです。
動画名.mp4— 日本語音声付き動画(YouTube本体にアップロード)動画名_en_dub.mp3— 英語吹き替え音声(BGM+SE含む)動画名_kr_dub.mp3— 韓国語吹き替え音声(BGM+SE含む)
この方式なら、トラックのミュート切り替えだけで各言語の音声を書き出せるので、言語が増えても手間はほとんど変わりません。視聴者が言語を切り替えたときも「音声だけが変わり、BGMやSEは同じ」という自然な体験になります。
さらに、元動画と各言語の吹き替え音声が同じタイムライン上にあるため、ここからショート動画を切り出す際にも吹き替え音声付きで書き出せます。ショート用に別途音声を用意する必要がなく、多言語ショート動画の量産にもそのまま対応できるのは大きなメリットです。
Step 7:YouTube Studioへのアップロード
- YouTube Studioで対象動画の編集画面を開く
- 「字幕」タブから対象言語を追加
- 「ダブ(吹き替え)を追加」を選択
- Step 6で作成した完成版MP3ファイルをアップロード
YouTubeの吹き替え音声は 元動画と長さが完全一致 していなければ登録できません。Step 4でタイムライン配置方式(単純連結ではなく、元動画のタイムコード位置にffmpegで各cueを配置)を採用したのはこのためです。この方式により、途中のcueが多少長くても短くても、全体の尺は常に元動画と一致します。
視聴者は動画の設定メニュー(歯車アイコン)から音声言語を切り替えて視聴できます。
コストと運用の目安
ElevenLabsのeleven_flash_v2_5モデルは 1文字あたり0.5クレジット です。
実測コスト(11分の動画)
実際に11分の動画を英語と韓国語に吹き替えたときの消費クレジットは以下の通りです。
| 言語 | 消費クレジット |
|---|---|
| 英語 | 4,452 |
| 韓国語 | 2,199 |
ElevenLabsは 文字数課金 なので、1文字あたりの情報密度が高い言語ほどコスパが良くなります。
| 言語 | 英語を100%とした場合のコスト比 |
|---|---|
| 中国語 | 35〜40% |
| 韓国語 | 約45% |
| 日本語 | 50〜55% |
| 英語 | 100%(基準) |
| ドイツ語 | 110〜120% |
ドイツ語は複合語が長くなる傾向があるため、英語より割高になります。
日本円でのコスト感
1USD=158円として、11分の動画を英語+韓国語�に吹き替えた場合のコストは以下の通りです。
| プラン | 月額 | クレジット | 英語音声 | 韓国語音声 | 合計 |
|---|---|---|---|---|---|
| Starter | $5 | 30,000 | 117円 | 58円 | 175円 |
| Creator | $22 | 100,000 | 155円 | 76円 | 231円 |
Starter Planでも11分の動画1本あたり175円程度で2言語対応できます。月間30,000クレジットなので、同程度の動画なら月に4〜5本は処理できる計算です。
コスト削減のポイント
コスト削減の本質は テキスト文字数の削減 です。contractionの活用("do not" → "don't")や冗長な表現のカット("Furthermore" → "Also")で5〜10%の削減が見込めます。モデルやオーディオフォーマットの変更ではクレジット消費は変わりません。
まとめ
この記事では、ElevenLabs APIとPython + ffmpegを組み合わせた多言語吹き替え音声の自動生成ワークフローを紹介しました。
全体の流れをおさらいします。
- Premiere ProやWhisper で日本語テキストを生成し、Python + Claude で前処理・整形する
- Claude で翻訳しTTS最適化された 吹き替え用字幕 を作成する
- ElevenLabs API で各cueからMP3音声を生成する
- ffmpeg の
adelay+amixで絶対時刻ベースのタイムラインを構築する - ゲイン調整とリミッタで マスタリング し、吹き替え音声MP3を出力する
- Premiere Pro で主音声をミュートし、BGM・SEと合成して完成版MP3を作成する
- YouTube Studio に吹き替え音声としてアップロードする
このワークフローの肝は2つあります。1つ目は Claudeによるテキスト処理 (Step 1〜2)。口語の整形、ニュアンスを維持した翻訳、時間枠に合わせたテキスト圧縮――これらは意味理解が必要な作業であり、Pythonスクリプトだけでは実現できません。2つ目は 絶対時刻配置 (Step 4)。単純連結ではなくffmpegで元動画のタイムコード位置に各cueを配置する方式により、出力の尺が確実に元動画と一致します。YouTubeの吹き替え音声は元動画と長さが完全一致している必要があるため、この設計が不可欠です。
ElevenLabsは月額$5から、Claudeも無料プランから利用でき、個人チャンネルの多言語展開への敷居はかなり下がっています。海外視聴者へのリーチを広げたい方は、ぜひ試してみてください。